Chào ae,
Đa số ae ở đây toàn cào dữ liệu nên mình muốn chia sẻ một vài kỹ thuật đã làm cũng như một số thách thức của mình, đây là những kỹ thuật mình đang và sẽ áp dụng trong spider bot của mình:
1. Hỗ trợ scale-out spiders
Khi cào dữ liệu số liệu ít, giả sử 1 spider cào trung bình 40k pages/day (khoảng 2s/page) thì việc bạn viết các spider riêng cho từng victim sites của bạn khá dễ. Ví dụ hình sau mô tả việc cào dữ liệu của 1 site với tầm hơn 4 triệu dữ liệu.

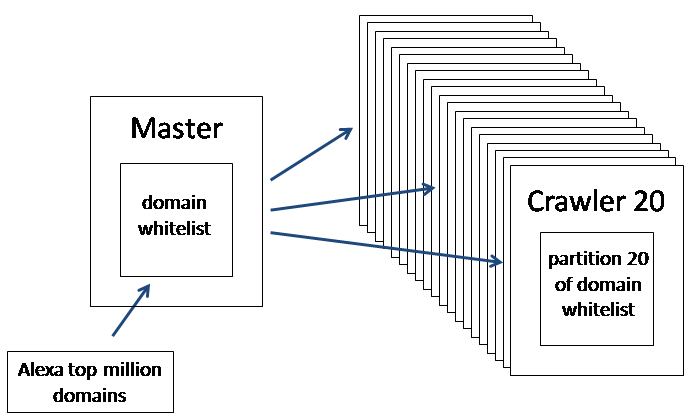
Tuy nhiên, nếu bạn muốn cào sites nhanh hơn mức 40k pages/day một ngày, giả sử 1M pages/day (cho nhiều victim sites) thì chắc chắn bạn cần tăng số spiders lên (nhu cầu cần 22 spiders hoặc tăng luồng tuỳ theo CPU bạn sở hữu), trong khi chia sẻ cùng 1 danh sách URLs. Khi đó bạn cần: hỗ trợ scale-out spiders (chạy spider trên servers hoặc VPS khác nhau) và 1 queue URLs DB (1 vps hoặc nhiều vps hỗ trợ HA). Ví dụ như hình sau:
 2. Anti-bot detection
2. Anti-bot detection
Khi cào dữ liệu thì bạn có thể gặp những websites sử dụng các cơ chế chặn bot (dĩ nhiên họ sẽ ko chặn các Search engine nổi tiếng như Google, Bing,... rồi). Họ có thể sẽ sử dụng các cơ chế:
- Phát hiện user-agents truy cập nhiều —> Giải pháp: dùng user-agent khác nhau hoặc dùng SE agents nổi tiếng cho mỗi lần request. Danh sách 450 User-Agents download tại
http://cafemmo.club/threads/chia-se-danh-sach-user-agent-thong-dung-nhat.1818/
- Phát hiện IPs truy cập nhiều, giả sử 5 requests/s --> Giải pháp: dùng các dịch vụ IP rotator cho mỗi lần request. Mình dùng stormproxies(.)com.
- Phát hiện người dùng thật qua Javascript, đa số bot ko hỗ trợ JS mà --> Giải pháp: dùng headless browser như Splash, Selenium, PhantomJS, Puppeter,... Có khá nhiều sites mình gặp dùng JS để detect robot như similarweb(.)com,...
- Sử dụng honeypot traps: ví dụ như các links bẩy đính kèm display:none, visibility: hidden,... --> cài đặt cơ chế phát hiện các traps thôi ^^
- Sử dụng cookie, captcha để chặn, đa số sites dùng Cloudflare để chặn bot --> có vài script bypass Cloudflare rồi, sử dụng như
https://github.com/Anorov/cloudflare-scrape (script này bypass cookie của Cloudflare nhưng chưa có cơ chế bypass captcha của Cloudflare nhé).
3. Ghi kết quả dữ liệu (scraped data) quá nhiều
Khi bạn cào dữ liệu với nhiều spiders, ví dụ 1 spider cào được 1 record/2s, và bạn có 20 spiders thì bạn có 10 records/s, lúc này việc ghi dữ liệu quá nhiều và liên tục vào DB sẽ làm cho DB của bạn quá tải và giảm hiệu năng, có thể ảnh hưởng đến hiệu năng hoạt động. Khi đó, bạn nên cân nhắc dùng:
- Bulk insert query: tức spider chỉ cần thực hiện 1 query để insert nhiều records
- Bulk import file: tức là spider ghi dữ liệu vào 1 file với 1000 dữ liệu chẳng hạn, sau đó bạn sử dụng lệnh import file đó vào DB. Ví dụ: MySQL (LOAD DATA LOCAL INFILE), MongoDB (mongoimport)
Các DB engines nào cũng hỗ trợ 2 dạng trên, ví dụ như MySQL, MongoDB,...
4. Cấu trúc site thay đổi
Ví dụ như site thay đổi layout, tức HTML tags thay đổi, lúc này bạn phải thay đổi các selectors để lấy đúng dữ liệu bạn cần. Trong tình huống này, spider cần có cơ chế phát hiện sự thay đổi cấu trúc site để thông báo cho chúng ta và dừng extract data của site đó. Khi đó, mỗi site ta cần hỗ trợ nhiều schemas để extract dữ liệu hơn.
Trên đây là một vài kỹ thuật chia sẻ cùng các bạn, nếu bạn biết kỹ thuật bypass tốt hơn hoặc khi cào dữ liệu mà bị các kỹ thuật chặn khác thì cùng chia sẻ để chúng ta cải tiến spider bot của chúng ta hơn nhé!
Happy crawling strategy ^^
